hive> desc function abs; OK tab_name abs(x) - returns the absolute value of x
详细显示自带的函数的用法
1 2 3 4 5 6 7 8 9 10 11
hive> desc function extended abs; OK tab_name abs(x) - returns the absolute value of x Example: > SELECT abs(0) FROM src LIMIT 1; 0 > SELECT abs(-5) FROM src LIMIT 1; 5 Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFAbs Function type:BUILTIN
常用内置函数
空字段赋值-NVL(防止空字段参与计算)
函数说明
1 2 3 4 5 6 7 8 9
hive(default)> desc function extended nvl; OK tab_name nvl(value,default_value) - Returns default value if value is null else returns value Example: > SELECT nvl(null,'bla') FROM src LIMIT 1; bla Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFNvl Function type:BUILTIN
hive (default)> select ename,comm,nvl(comm, 0) comm_0 from emp; OK ename comm comm_0 fanfan 500000.0 500000.0 SMITH NULL 0 ALLEN 300.0 300.0 WARD 500.0 500.0 ……
[root@hadoop datas]$ vim emp_sex.txt 悟空,A,男 大海,A,男 宋宋,B,男 凤姐,A,女 婷姐,B,女 婷婷,B,女
创建emp_sex表并导入数据
1 2 3 4 5 6 7
hive(default)> create table emp_sex( name string, dept_id string, sex string ) row format delimited fields terminated by ","; hive(default)> load data local inpath '/opt/module/hive/datas/emp_sex.txt' into table emp_sex;
需求:求出不同部门男女各多少人。结果如下:
1 2 3
dept_id man_num woman_num A 2 1 B 1 2
按需求查询数据
1 2 3 4 5 6 7
hive(default)> select dept_id, sum(case sex when '男' then 1 else 0 end) man_num, sum(case sex when '女' then 1 else 0 end) woman_num from emp_sex group by dept_id;
hive (default)> desc function extended concat; OK tab_name concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data bin1, bin2, ... binN Returns NULL if any argument is NULL. Example: > SELECT concat('abc', 'def') FROM src LIMIT 1; 'abcdef' Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFConcat Function type:BUILTIN
CONCAT_WS(separator, str1, str2,…):
1 2 3 4 5 6 7 8 9 10
hive (default)> desc function extended concat_ws; OK tab_name concat_ws(separator, [string | array(string)]+) - returns the concatenation of the strings separated by the separator. Example: > SELECT concat_ws('.', 'www', array('facebook', 'com')) FROM src LIMIT 1; 'www.facebook.com' Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFConcatWS Function type:BUILTIN
- 它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。
- 分隔符可以是与剩余参数一样的字符串。
- 如果分隔符是 NULL,返回值也将为 NULL。
- 这个函数会跳过分隔符参数后的任何 NULL 和空字符串。
- 分隔符将被加到被连接的字符串之间;
- 注意: CONCAT_WS must be "string or array<string>
COLLECT_SET(col):
1 2 3 4 5 6
hive (default)> desc function extended collect_set; OK tab_name collect_set(x) - Returns a set of objects with duplicate elements eliminated Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDAFCollectSet Function type:BUILTIN
[root@hadoop datas]$ vim person_info.txt 孙悟空,白羊座,A 大海,射手座,A 宋宋,白羊座,B 猪八戒,白羊座,A 凤姐,射手座,A 苍老师,白羊座,B
案例实操
创建person_info表并导入数据
1 2 3 4 5 6
hive (default)> create table person_info( name string, constellation string, blood_type string ) row format delimited fields terminated by ",";
导入数据到person_info表中。
1 2
hive (default)> load data local inpath "/opt/module/hive/datas/person_info.txt" into table person_info;
按需求查询数据
1 2 3 4 5 6 7 8 9 10
hive (default)> SELECT t1.c_b, CONCAT_WS("|",collect_set(t1.name)) FROM ( SELECT NAME , CONCAT_WS(',',constellation,blood_type) c_b FROM person_info )t1 GROUP BY t1.c_b
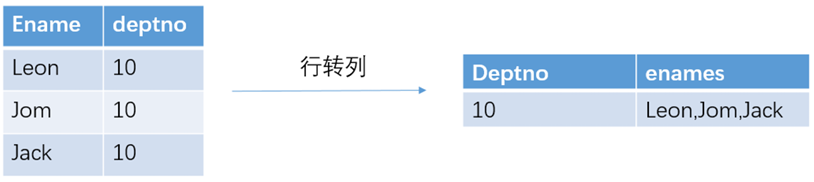
列转行
函数说明
EXPLODE(col):将hive表的一列中复杂的array或者map结构拆分成多行。
1 2 3 4 5 6 7
hive (default)> desc function extended explode; OK tab_name explode(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDTFExplode Function type:BUILTIN
hive (default)> desc function extended split; OK tab_name split(str, regex) - Splits str around occurances that match regex Example: > SELECT split('oneAtwoBthreeC', '[ABC]') FROM src LIMIT 1; ["one", "two", "three"] Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFSplit Function type:BUILTIN
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
《疑犯追踪》 悬疑 《疑犯追踪》 动作 《疑犯追踪》 科幻 《疑犯追踪》 剧情 《Lie to me》 悬疑 《Lie to me》 警匪 《Lie to me》 动作 《Lie to me》 心理 《Lie to me》 剧情 《战狼2》 战争 《战狼2》 动作 《战狼2》 灾难
案例实操
在/opt/module/hive/datas/目录下创建文件movie.txt,添加如下数据:
1 2 3 4
[root@hadoop datas]$ vim movie_info.txt 《疑犯追踪》 悬疑,动作,科幻,剧情 《Lie to me》 悬疑,警匪,动作,心理,剧情 《战狼2》 战争,动作,灾难
创建hive表并导入数据
1 2 3 4 5 6 7
hive (default)> create table movie_info( movie string, category string) row format delimited fields terminated by "\t"; hive (default)> load data local inpath "/opt/module/hive/datas/movie_info.txt" into table movie_info;
按需求查询数据
1 2 3 4
hive (default)> SELECT movie,category_name FROM movie_info lateral VIEW explode(split(category,",")) movie_info_tmp AS category_name ;
Function(arg1 ……) over([partition by arg1 ……] [order by arg1 ……] [<window_expression>])
Function
Over()
window_expression
解释:
支持的函数
解释:
指定分析函数工作的数据 窗口大小,窗口会随着行 的变化而变化。
解释:
窗口边界的设置
聚合函数:
sum()、max()、 min()、avg() 等。
Partition by:
表示将数据先按字段进行分区
n preceding
往前n行
n following
往后n行
排序函数:
rank(), row_number()、 dens_rank()、 ntile()等。
current row
当前行
Order by:
表示将各个分区内的数据按字段 进行排序
unbounded preceding
从前面的起点开始
lead()、 lag()、 first_value() 等。
unbounded following
到后面的终点结束
使用详解
如果不指定partition by,则不对数据进行分区,换句话说,所有数据看作同一个分区。
如果不指定order by, 则不对各分区进行排序,通常用于那些顺序无关的窗口函数,如sum()。
如果不指定窗口子句:
不指定order by,默认使用分区内所有行,等同于Function() over(rows between unbounded precedeing and unbounded following) 如果指定order by,默认使用分区内第起点到当前行,等同于Function() over(rows between unbounded preceding and current row)
hive(default)> create table business( name string, orderdate string, cost int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; hive(default)> load data local inpath "/opt/module/hive/datas/business.txt" into table business;
hive(default)> create table score( name string, subject string, score int) row format delimited fields terminated by "\t"; hive(default)> load data local inpath '/opt/module/hive/datas/score.txt' into table score;
hive (default)> add jar /opt/module/hive/datas/myudf.jar;
创建临时函数
创建临时函数与开发好的java class关联
1
hive (default)> create temporary function my_len as "com.atguigu.hive. MyStringLength";
在hql中使用自定义的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
hive (default)> select ename,my_len(ename) ename_len from emp; OK ename _c1 fanfan 6 SMITH 5 ALLEN 5 WARD 4 JONES 5 MARTIN 6 BLAKE 5 CLARK 5 SCOTT 5 KING 4 TURNER 6 ADAMS 5 JAMES 5 FORD 4 MILLER 6