
Power BI数据分析与可视化
浅小兮Power BI数据分析与可视化
Power BI 是由微软开发的一个商业智能工具,用于数据的收集、整理、分析以及可视化。它可以帮助企业和个人用户从多个数据源中提取数据,然后通过各种图表和报表形式进行可视化展示,以便更好地理解和分析数据。
以下绝大部分参考Power BI官方文档,转载请标注
–浅小兮
Power BI 的主要功能
- 数据连接:Power BI 可以连接到各种数据源,包括Excel、SQL数据库、Azure Data Lake、云服务、社交媒体平台等。
- 数据建模:用户可以对数据进行转换、计算和建模,以满足特定的分析需求。
- 数据可视化:Power BI 提供丰富的图表和仪表板组件,可以创建交互式的可视化图表和仪表板。
- 仪表板:用户可以将多个图表和表格组合成一个仪表板,以便在单一界面上查看和分析数据。
- 协作和共享:Power BI 支持多用户协作,可以分享和协作仪表板和报告。
- 移动访问:Power BI 提供移动应用,用户可以在手机或平板电脑上查看和分析数据。

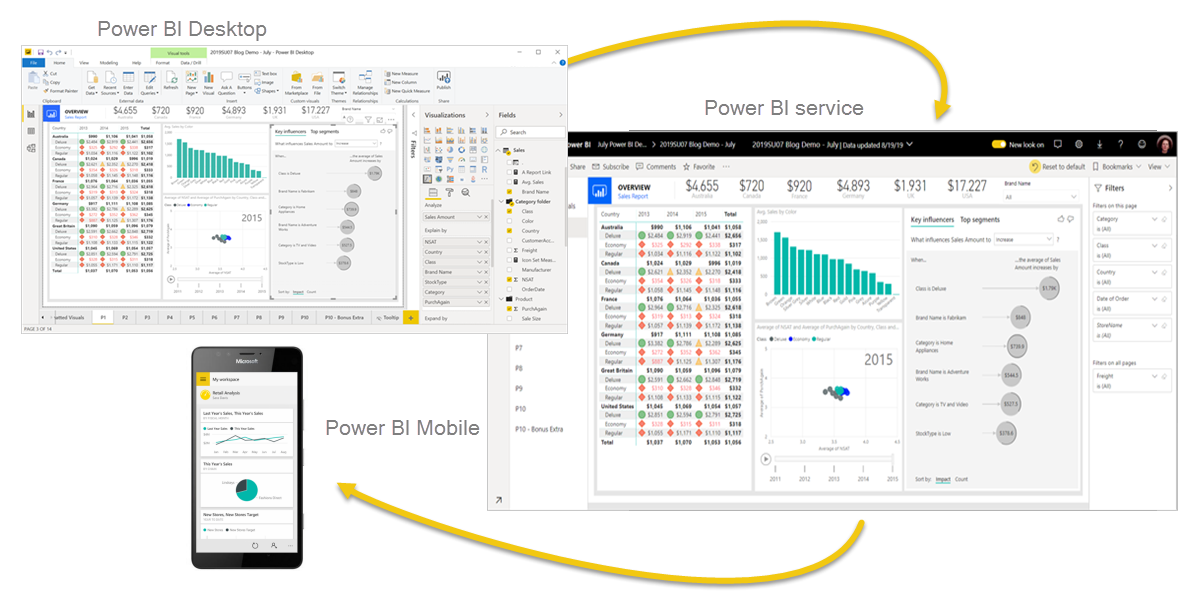
Power BI 的使用场景
-
企业分析:帮助企业分析销售、财务、客户关系等关键业务指标。
-
市场分析:通过社交媒体和在线数据源分析市场趋势和客户反馈。
-
项目监控:监控项目进度和关键绩效指标(KPIs)。
-
个人分析:帮助个人用户分析个人财务、健康数据等。
Power BI 的优点
-
用户友好:界面直观,不需要深入的编程知识。
-
功能强大:支持多种数据源和复杂的数据分析。
-
跨平台:可以在Windows、Mac、iOS和Android等平台上使用。
-
协作能力:支持多用户协作和共享。
-
集成能力:可以与Office 365、Azure和其他微软服务集成。
Power BI 的局限性
-
学习曲线:虽然用户友好,但一些高级功能可能需要一定的学习时间。
-
依赖性:与Office 365和Azure等微软服务紧密集成,可能需要额外的成本。
-
移动体验:虽然提供移动应用,但一些高级功能可能不如桌面版。
-
数据限制:某些免费版本可能对数据量有限制。
数据分析和可视化概述
数据分析和可视化是将数据转换为有意义的见解的过程,它涉及数据的收集、处理、分析和呈现。这一过程对于理解数据模式、趋势和关系至关重要,并为决策制定提供支持。以下是数据分析和可视化的一般概述:
数据分析
数据分析是指对数据进行探索和解释的过程,以提取有价值的信息。它包括以下步骤:
-
数据收集:从不同的源收集数据,如数据库、网络、传感器等。
-
数据清洗:处理数据中的缺失值、异常值、重复值等,确保数据的质量。
-
数据探索:使用统计方法和可视化工具来探索数据的基本特性,如分布、相关性等。
-
数据转换:将数据转换为适合分析的形式,可能包括数据聚合、归一化等。
-
数据分析:应用统计和机器学习技术来发现数据中的模式和趋势。
-
模型建立:根据分析结果建立预测模型或决策支持模型。
-
结果解释:解释分析结果,将数据转换为易于理解的信息。
可视化
数据可视化是将数据转换为图形或图像的过程,以便更直观地展示数据。它可以帮助人们更好地理解和解释数据。以下是一些常用的数据可视化工具和技术:
-
图表:包括柱状图、折线图、饼图、散点图等,用于展示数据的分布、趋势和关系。
-
仪表板:将多个图表组合在一起,形成一个综合的界面,用于监控和分析关键业务指标。
-
地图:用于展示地理位置数据,如人口分布、交通流量等。
-
时间序列分析:使用时间轴来展示数据随时间的变化。
-
3D可视化:在三维空间中展示数据,用于展示复杂的数据关系。
-
交互式可视化:允许用户通过点击、拖拽等操作来探索数据。
数据分析的目的
-
理解数据:通过分析数据,可以更好地理解数据集的结构和特征。
-
发现模式和趋势:数据分析可以帮助发现数据中的重复模式和趋势,从而揭示潜在的关联和因果关系。
-
决策支持:数据分析为决策制定提供数据驱动的见解,帮助个人和企业做出更明智的决策。
-
优化过程:通过分析数据,可以识别和改进流程中的瓶颈和问题。
-
预测未来:使用统计模型和机器学习技术,可以从历史数据中预测未来的趋势和结果。
数据分析的类型
-
描述性分析:描述数据的基本特征,如平均值、中位数、标准差等。
-
探索性分析:探索数据集,发现潜在的模式和关系。
-
预测性分析:使用统计模型和机器学习算法来预测未来的趋势和结果。
-
规范性分析:使用数学模型和统计方法来规范和优化决策过程。
数据分析的工具和技术
-
统计软件:如SPSS、SAS、R、Python等,用于执行各种统计分析和机器学习算法。
-
数据可视化工具:如Tableau、Power BI、QlikView等,用于将数据转换为图表和仪表板。
-
数据库管理系统:如MySQL、Oracle、SQL Server等,用于存储和查询大量数据。
-
云计算服务:如Amazon Web Services (AWS)、Microsoft Azure、Google Cloud Platform等,提供强大的计算和存储资源。
-
编程语言:如Python、R、Java等,用于编写数据分析脚本和算法。
获取数据
-
Power BI Desktop 获取数据:
- 本地文件:支持连接到 Excel、CSV、文本文件、JSON、XML 等多种本地文件格式。
- 数据库:支持连接到 SQL Server、Oracle、MySQL、Teradata、PostgreSQL 等关系型数据库。
- 云数据库:支持连接到 Azure SQL Database、Amazon Redshift、Snowflake 等云数据库。
- 大数据:支持连接到 Hadoop、Spark 等大数据平台。
- 数据流:支持连接到 Azure Data Factory、Azure Event Hubs、Azure IoT Hub 等数据流服务。
- 服务:支持连接到 SharePoint、OneDrive、Dropbox 等服务。
- 社交媒体:支持从 Twitter、Facebook 等社交媒体平台获取数据。
-
Power BI Service 获取数据:
- 导入文件:用户可以将本地文件上传到 Power BI Service,然后将其导入到 Power BI 仪表板中。
- 数据集:用户可以创建和管理数据集,并将其作为数据源连接到仪表板。
- Power BI 获取数据工具:Power BI 提供了专门的获取数据工具,如 Power BI Desktop 和 Power Query,用于从各种数据源中提取、转换和加载数据。
Power Query和M语言
Power Query
Power Query 是一个数据获取、转换和加载(ETL)工具,它允许用户从各种数据源中提取数据,并对数据进行清洗、转换和整合。Power Query 提供了一个图形化的界面,用户可以通过拖放和点击来操作数据,无需编写代码。它支持多种数据源,包括 Excel、文本文件、CSV、数据库、云服务等。
M 语言(M 表达式)
M 语言是 Power Query 的背后语言,它是一种基于表格的数据表达语言,用于定义数据转换和加载操作。M 语言允许用户编写更复杂的查询和数据处理逻辑,这些逻辑可以被保存并重复使用。M 语言具有以下特点:
-
表达式语言:基于表格的语法,类似于 Excel 公式。
-
功能强大:可以执行复杂的数据清洗、转换和加载任务。
-
可重用:M 语言表达式可以被保存为 M 查询,并在 Power BI Desktop 中重复使用。
-
编程能力:允许用户编写自定义函数和模块,以扩展 Power Query 的功能。
使用 M 语言
-
在 Power BI Desktop 中,点击“获取数据”选项卡。
-
选择“其他”类别,然后选择“M 查询”。
-
在弹出的对话框中,输入你的 M 语言表达式。例如,输入
=Table.FromList(List.FromValues(["张三", "李四", "王五"], ["姓名"]))来创建一个包含姓名的表格。 -
点击“确定”按钮,Power Query 将根据你的 M 语言表达式自动创建一个查询。
-
你可以在查询编辑器中进一步编辑和优化你的 M 语言表达式。
-
完成查询后,点击“加载”按钮,数据将被加载到 Power BI Desktop 中。在 Power BI 中,集成、清洗、转换和规约数据的操作步骤如下:
数据集成
以下操作步骤基于Power BI Desktop 2020版本写的,其他版本大差不差吧
-
打开 Power BI Desktop:启动 Power BI Desktop 应用程序。
-
获取数据:在左侧导航栏中,点击“获取数据”选项卡。
-
选择数据源:在“获取数据”选项卡中,选择你想要集成的数据源类型。
-
连接数据源:在弹出的对话框中,输入数据源的连接信息,如服务器名称、数据库名称、用户名和密码。
-
选择数据:在连接到数据源后,选择你想要集成的数据表和列。
-
加载数据:点击“加载”按钮,将数据加载到 Power BI Desktop 中。
数据清洗
-
数据预览:在 Power BI Desktop 中,双击数据表,打开数据编辑器。
-
处理缺失值:在数据编辑器中,使用“值”选项卡中的“填充”功能来处理缺失值。
-
处理异常值:在数据编辑器中,使用“值”选项卡中的“检测异常”功能来识别异常值。
-
数据清洗规则:在数据编辑器中,使用“值”选项卡中的“自定义”功能来应用自定义清洗规则。
-
保存数据:在数据编辑器中,点击“关闭并加载到 Power BI”按钮,将清洗后的数据加载到 Power BI 中。。
数据清洗通常包括以下几个关键方面:
-
缺失值处理:
- 删除:直接删除包含缺失值的记录或字段。
- 填充:使用特定方法(如平均值、中位数、最频繁值)来填充缺失值。
- 插值:使用数学方法(如线性插值、样条插值)来估计缺失值。
-
异常值检测与处理:
- 检测:使用统计方法(如箱线图、Z分数)来识别异常值。
- 处理:根据业务规则和数据质量标准决定如何处理异常值,可能包括删除、标记或调整。
-
数据一致性检查:
- 检查数据格式的一致性,如日期、时间、货币符号等。
- 检查数据单位的一致性,如长度、重量、温度等。
- 检查数据名称和标签的一致性,确保字段和记录的名称清晰、准确。
-
数据标准化:
- 将数据转换为一致的格式和单位,如标准化日期格式、货币符号等。
- 标准化数据范围和分布,如将所有数值转换为同一量级。
-
数据验证:
- 验证数据的准确性、完整性和一致性。
- 进行交叉验证,比较不同数据源中的相同信息,确保数据的一致性。
注意!!!不完整数据也称为缺失数据或缺失值,是指在数据集中缺少某些数据点。噪声数据是指数据集中包含的随机或不相关的错误数据,这些数据可能会干扰分析结果,导致错误的结论。
数据转换
-
数据合并:在 Power BI Desktop 中,使用“获取数据”选项卡中的“合并”功能来合并数据。
-
数据计算:在数据编辑器中,使用“值”选项卡中的“计算”功能来创建新的数据字段或计算现有字段的值。
-
数据格式化:在数据编辑器中,使用“格式”选项卡中的功能来格式化数据。
-
数据验证:在 Power BI Desktop 中,使用“数据”选项卡中的“验证”功能来验证转换后的数据。
-
保存数据:在数据编辑器中,点击“关闭并加载到 Power BI”按钮,将转换后的数据加载到 Power BI 中。
(关键步骤)数据转换通常包括以下几个关键方面:
-
数据合并:将来自不同数据源的数据合并在一起,形成一个统一的数据集。这可能涉及到数据的关联和匹配。
-
数据计算:创建新的数据字段或计算现有字段的值,如计算平均值、总和、比例等。这有助于生成更丰富的数据集,为分析提供更多维度。
-
数据格式化:将数据转换为特定的格式,如日期格式、货币格式、百分比格式等。这有助于提高数据的可读性和分析的准确性。
-
数据标准化:将数据转换为同一量级或标准格式,以便于比较和分析。例如,将所有数值转换为同一量级,或将分类数据转换为数值数据。
-
数据验证:验证转换后的数据是否符合需求,包括数据格式、数据完整性等。这有助于确保数据的质量和一致性。
-
数据归一化:将数据缩放到一个特定的范围,以便于比较和分析。例如,将所有数值数据缩放到0到1之间。
数据归约
-
数据采样:在 Power BI Desktop 中,使用“数据”选项卡中的“采样”功能来从原始数据中抽取一部分数据。
-
特征选择:在 Power BI Desktop 中,使用“建模”选项卡中的“度量值”功能来选择最相关的特征。
-
维度归约:在 Power BI Desktop 中,使用“建模”选项卡中的“维度”功能来减少数据集的维度。
-
数据验证:在 Power BI Desktop 中,使用“数据”选项卡中的“验证”功能来验证归约后的数据。
-
保存数据:在 Power BI Desktop 中,点击“关闭并加载到 Power BI”按钮,将归约后的数据加载到 Power BI 中。
规约数据的方法包括:
-
数据采样:从原始数据中抽取一部分数据,以代表整个数据集的特征。这可以用于快速分析和测试。
-
特征选择:从数据集中选择最相关的特征,以减少模型的复杂性和提高性能。这可以通过统计方法(如相关性分析)或机器学习算法(如主成分分析)来实现。
-
维度规约:通过降维技术来减少数据集的维度。这包括主成分分析(PCA)、线性判别分析(LDA)等方法,它们可以将高维数据转换为低维数据,同时保留数据的主要信息。
-
数据压缩:使用数据压缩技术来减少数据的存储空间。这可以通过去除数据中的冗余信息或使用压缩算法来实现。
-
数据摘要:创建数据的摘要或概要,以减少数据的大小。这可以通过汇总数据、创建摘要统计量或使用数据摘要技术来实现。
字段归约
字段归约(Field Reduction)是数据归约(Data Reduction)的一种形式,又称维归约,属性归约或属性子集选着,它专注于减少数据集中字段的数量,同时尽可能保留数据的有用信息。字段归约的目的是减少数据存储和处理的需求,同时确保数据集的完整性和分析的有效性。在 Power BI 中,字段归约可以通过以下步骤实现:
-
数据导入:
- 导入原始数据集到 Power BI Desktop。
-
数据预览:
- 打开数据集,查看各个字段的值和分布。
-
特征选择:
- 确定哪些字段对于分析任务是必要的,哪些是冗余的。
- 使用统计方法(如相关性分析)或业务知识来评估字段的重要性。
-
数据转换:
- 删除不重要的字段,保留关键的字段。
- 如果有必要,可以将多个相关的字段合并成一个新字段。
-
数据验证:
- 验证归约后的数据集是否仍然满足分析需求。
- 确保关键信息没有被遗漏。
-
模型评估:
- 使用归约后的数据集创建模型和报表。
- 评估模型的性能和分析结果的准确性。
-
迭代优化:
- 根据分析结果和业务需求调整字段归约策略。
- 重复归约过程,直到达到满意的结果。
-
文档记录:
- 记录字段归约的步骤、方法和结果。
- 确保归约数据的处理过程可重复和可审计。
DAX语言数据建模
DAX(Data Analysis eXpressions)是Power BI和Power Pivot中的一个扩展性语言,用于数据建模和分析。DAX提供了一套丰富的函数和表达式,允许用户创建和管理多维数据模型。以下是DAX语言数据建模的一些关键概念和功能:
-
度量值(Measures):
- 度量值是在Power BI或Power Pivot模型中的计算值。
- 度量值通常用于计算如总和、平均值、最大值、最小值等聚合函数。
- 度量值可以基于数据模型中的事实表和维度表。
-
计算列(Calculated Columns):
- 计算列是存储在事实表或维度表中的计算值。
- 计算列可以包含复杂的计算和逻辑,如日期计算、文本连接等。
- 计算列可以帮助用户扩展数据模型的功能,但它们不直接用于多维数据集的聚合。
-
表(Tables):
- 表是Power BI或Power Pivot模型中的数据结构。
- 表可以包含事实数据或维度数据。
- 表可以与其他表通过关系连接起来。
-
关系(Relationships):
- 关系是表之间的连接,用于确保数据的一致性和准确性。
- 关系可以基于表之间的键(如外键)来创建。
- 关系有助于Power BI和Power Pivot在数据集之间创建引用和链接。
-
KPI(Key Performance Indicators):
- KPI是用于跟踪业务性能的度量值。
- KPI可以设置目标值、警告值和目标跟踪线。
- KPI有助于用户监控和分析关键业务指标。
-
时间智能(Time Intelligence):
- 时间智能是DAX中的一个功能集,用于处理和分析时间序列数据。
- 时间智能包括日期时间函数、时间序列聚合函数等。
- 时间智能有助于用户创建动态的时间序列分析。
-
层次结构(Hierarchies):
- 层次结构是维度表中的结构,用于组织数据。
- 层次结构可以包含多个级别,如年度、季度、月份等。
- 层次结构有助于用户在多维数据集中进行多级分析。
-
集(Sets):
- 集是DAX中的一个数据结构,用于存储一组值。
- 集可以基于查询结果或表达式创建。
- 集有助于用户进行复杂的分析,如过滤数据、创建动态的计算等。
认识Power Pivot和DAX语言
Power Pivot 和 DAX(Data Analysis Expressions)语言是 Microsoft Excel 中的两个强大功能,它们允许用户处理大量数据并进行复杂的数据分析。
Power Pivot
Power Pivot 是一个免费的 Excel 加载项,它将 Excel 转变成了一个强大的数据分析和处理工具。Power Pivot 允许用户创建数据模型,这些模型可以包含大量的数据,并且可以处理复杂的关系和计算。以下是 Power Pivot 的一些关键特点:
-
内存中处理:Power Pivot 使用内存中数据库技术(也称为 xVelocity 内存分析引擎),这意味着它可以将大量数据加载到内存中进行快速处理。
-
数据模型:Power Pivot 允许用户创建一个关系型数据模型,这个模型可以包含多个表和它们之间的关系。
-
计算列:用户可以在 Power Pivot 中创建计算列,这些列的值是基于表中其他列的值计算得出的。
-
度量值:度量值是使用 DAX 公式创建的动态计算,它们在查询时实时计算,不存储在模型中。
-
数据透视表和图表:Power Pivot 可以与 Excel 的数据透视表和图表集成,使用户能够创建复杂的报告和可视化。
DAX 语言
DAX 是一种公式语言,用于在 Power Pivot 中创建计算列和度量值。DAX 提供了一系列函数和运算符,用于执行各种数据操作和计算。以下是 DAX 的一些关键特点:
-
函数库:DAX 提供了大量的内置函数,包括聚合函数(如 SUM、AVERAGE)、日期和时间函数(如 YEAR、MONTH)、逻辑函数(如 IF、 SWITCH)等。
-
上下文:DAX 计算依赖于行上下文和筛选上下文。行上下文指的是当前正在处理的行,而筛选上下文是应用于数据模型的筛选条件,它决定了度量值的计算范围。
-
时间智能:DAX 包含一系列时间智能函数,这些函数简化了与日期和时间相关的计算,如计算同期比较、年内累计等。
-
兼容性:DAX 语言与 Excel 公式语言相似,但它专为 Power Pivot 和数据分析而设计,因此在某些方面与 Excel 公式有所不同。
-
性能优化:DAX 允许用户通过编写高效的公式来优化数据模型的性能,这对于处理大量数据尤为重要。
Power Pivot 和 DAX 的应用场景
-
大数据分析:当 Excel 中的数据量超过常规处理能力时,Power Pivot 可以处理数百万行的数据。
-
复杂的数据关系:Power Pivot 可以轻松处理多个表之间的复杂关系,这对于分析大型企业数据尤其有用。
-
动态报告:使用 DAX 度量值可以创建动态报告,这些报告可以根据用户的筛选和交互实时更新。
-
时间序列分析:DAX 的时间智能函数使得分析时间序列数据变得简单,如计算 月销售总额、同比增长等。
新建数据表中的元素
在 Power BI 中新建数据表的步骤如下:
1. 导入数据
-
打开 Power BI Desktop。
-
点击“获取数据”按钮,选择数据源,如 Excel、SQL Server、CSV 文件等。
-
导入数据,并根据需要进行数据清洗和转换。
2. 创建新表
-
在“数据视图”中,点击“新建表”按钮。
-
输入表名称。
3. 添加列
-
在新建的表中,点击“添加列”按钮。
-
输入列名称。
-
选择数据类型,如文本、数字、日期/时间、布尔值等。
4. 设置数据类型
-
为每列选择合适的数据类型,以确保数据的准确性和性能。
5. 设定主键
-
选择一个或多个列作为主键,以唯一标识表中的每一行。
6. 数据验证和约束
-
根据需要设置数据验证规则来限制用户输入的数据类型或值。
-
约束可以确保数据的准确性和一致性。
7. 建立关系
-
如果您的数据模型包含多个表,您需要定义表之间的关系。
-
关系通常基于共同的列(如客户 ID、订单 ID 等)。
8. 添加计算列
-
如果需要在表中基于现有数据创建新的列,可以使用 DAX 公式来创建计算列。
-
在“数据视图”中,选择表,然后点击“新建列”按钮,输入 DAX 公式。
9. 定义度量值
-
度量值是使用 DAX 公式创建的动态计算,它们在查询时实时计算,不存储在模型中。
-
在“数据视图”中,点击“新建度量值”按钮,输入 DAX 公式。
10. 测试和验证
-
确保计算列和度量值的计算结果准确无误。
-
检查数据模型和 DAX 表达式的性能,确保高效运行。
数据分析可视化
参考官方文档,就不详细写如何作图的了太麻烦了
数据分析可视化是将数据转换为图形或图像的过程,以便更容易理解和解释数据中的模式、趋势和关联。良好的数据可视化可以帮助决策者更快地理解复杂的数据集,从而做出更明智的决策。以下是一些常见的数据分析可视化工具和技术:
常见的数据可视化类型:
-
柱状图:用于展示分类数据的不同组之间的比较。
-
折线图:用于展示随时间或其他连续变量而变化的数据趋势。
-
饼图:用于显示组成整体的部分占比。
-
散点图:用于展示两个变量之间的关系。
-
热力图:使用颜色来表示数据强度的二维图表。
-
地图:用于地理数据的可视化,展示地区之间的比较或分布。
-
雷达图:用于显示多个量化变量的数据点。
-
箱线图:用于展示数据的分布,包括中位数、四分位数和异常值。
认识可视化设计
以下是可视化设计的一些关键概念和最佳实践:
关键概念:
-
清晰性:可视化应该清晰、直观,避免混淆或误导用户。
-
简洁性:设计应该简洁,避免不必要的装饰,以便用户专注于数据。
-
一致性:在整个可视化中保持一致的布局、颜色和字体,以增强用户体验。
-
色彩运用:使用颜色来强调重要信息,但要避免使用过多或冲突的颜色。
-
交互性:提供交互功能,如筛选、缩放和详细信息显示,以提高用户体验。
-
适应性:设计应该能够适应不同的设备和屏幕尺寸。
最佳实践:
-
了解受众:在设计可视化之前,了解你的受众和他们需要从数据中得到的信息。
-
选择合适的图表:根据数据类型和分析目标选择最合适的图表类型。
-
避免信息过载:避免在单个可视化中包含过多的数据点或信息,这可能会使用户感到困惑。
-
使用标题和标签:为每个可视化添加清晰的标题和轴标签,以提供上下文。
-
优化布局:使用适当的布局来组织可视化,以便用户可以轻松地比较和分析数据。
-
考虑颜色盲用户:使用颜色盲友好的颜色方案,以确保所有用户都能理解可视化。
-
测试和迭代:在设计过程中进行用户测试,并根据反馈进行调整。
掌握对比分析
对比分析是一种数据分析方法,用于比较两个或多个数据集以找出它们之间的相似之处和差异。这种分析方法可以帮助决策者识别关键趋势、模式、异常和潜在的原因。以下是掌握对比分析的一些关键步骤和技巧:
关键步骤:
-
定义比较目标:明确你想要通过对比分析达到的目的或解决的问题。
-
选择数据集:选择需要比较的数据集。这些数据集可能来自不同的时间点、不同的地区、不同的产品等。
-
清洗和准备数据:确保所有数据集都是干净的、格式一致的,并且具有可比性。
-
选择比较维度:确定你将如何比较这些数据集。这可能包括定量指标(如销售额、利润)和定性指标(如客户满意度、品牌知名度)。
-
进行对比分析:使用统计方法、可视化工具或仪表板来比较数据集。
-
识别差异和相似性:分析结果,找出数据集之间的关键差异和相似性。
-
解释和分析原因:探讨导致这些差异和相似性的可能原因。
-
制定行动计划:根据分析结果,制定改进策略或行动计划。
技巧和工具:
-
使用图表和可视化:利用柱状图、折线图、散点图等可视化工具来直观地展示数据集之间的比较。
-
计算关键指标:计算平均值、中位数、标准差等统计指标来量化数据集之间的差异。
-
趋势分析:查看随时间的变化趋势,以了解数据集随时间的变化情况。
-
细分市场:将数据集细分为不同的子集或市场,以深入了解特定群体或产品类别的表现。
-
使用比率分析:计算比率(如利润率、回报率)来比较不同数据集的效率。
-
进行交叉分析:结合多个维度进行分析,以获得更全面的理解。
-
考虑外部因素:分析外部因素(如经济环境、竞争对手行为)如何影响数据集。
-
使用专业工具:利用Excel、Power BI、Tableau等数据分析工具来简化对比分析过程。
掌握结构分析
结构分析是一种数据分析方法,它涉及对数据集的内部组成和结构进行研究,以理解各部分如何相互关联和影响整体。结构分析可以帮助决策者识别关键组成部分、比例、分布和趋势,从而做出更明智的决策。以下是掌握结构分析的一些关键步骤和技巧:
关键步骤:
-
定义分析目标:明确你想要通过结构分析达到的目的或解决的问题。
-
收集和准备数据:确保所有需要的数据都是可用的,并且是干净、格式一致的。
-
确定分析维度:选择你将分析的维度,例如产品、地区、客户群体等。
-
计算组成部分:计算每个组成部分的数值,如销售额、市场份额等。
-
分析比例和分布:研究各组成部分在整体中的比例和分布,以识别关键趋势和模式。
-
进行趋势分析:查看随时间的变化趋势,以了解各组成部分随时间的变化情况。
-
解释和分析原因:探讨导致这些比例和分布的原因,以及它们对整体的影响。
-
制定行动计划:根据分析结果,制定改进策略或行动计划。
技巧和工具:
-
使用图表和可视化:利用饼图、堆叠柱状图、树状图等可视化工具来直观地展示数据的结构和比例。
-
计算关键指标:计算百分比、增长率、集中度等指标来量化各组成部分的重要性。
-
细分市场:将数据细分为不同的子集或市场,以深入了解特定群体或产品类别的表现。
-
进行交叉分析:结合多个维度进行分析,以获得更全面的理解。
-
考虑外部因素:分析外部因素(如经济环境、竞争对手行为)如何影响数据的结构。
-
使用专业工具:利用Excel、Power BI、Tableau等数据分析工具来简化结构分析过程。
掌握相关分析
相关分析是一种统计方法,用于衡量两个变量之间的线性关系强度和方向。它可以帮助我们理解变量是如何一起变化的,以及一个变量的变化是否与另一个变量的变化有关。以下是掌握相关分析的一些关键步骤和技巧:
关键步骤:
-
定义研究目标:明确你想要通过相关分析探究的问题或假设。
-
选择变量:选择你想要分析的变量。这些变量应该是可量化的,并且你有足够的数据来进行分析。
-
收集数据:确保所有需要的数据都是可用的,并且是干净、格式一致的。
-
检查数据质量:在进行相关分析之前,检查数据是否存在缺失值、异常值或错误。
-
计算相关系数:使用相关系数(如皮尔逊相关系数)来计算两个变量之间的线性关系。相关系数的值范围从-1到1,其中1表示完全正相关,-1表示完全负相关,0表示没有线性相关。
-
解释相关系数:根据相关系数的值和符号,解释两个变量之间的关系强度和方向。
-
进行显著性检验:通常需要检验相关系数的显著性,以确定观察到的相关是否具有统计学意义。
-
考虑其他因素:相关分析只能告诉我们变量之间的线性关系,它可能隐藏了非线性关系或其他因素的影响。
技巧和工具:
-
使用散点图:通过散点图可视化两个变量之间的关系,可以帮助直观地理解数据。
-
检查假设条件:皮尔逊相关系数要求变量是连续的、正态分布的,并且之间的关系是线性的。确保这些假设条件得到满足。
-
考虑替代相关系数:如果数据不满足皮尔逊相关系数的假设,可以考虑使用斯皮尔曼等级相关系数或肯德尔等级相关系数。
-
进行多重比较:如果分析中涉及多个变量,考虑进行多重比较,以控制错误发现率。
-
使用专业工具:利用Excel、R、Python、SPSS等统计软件进行相关分析,这些工具提供了相关系数的计算和显著性检验。
认识描述性分析
描述性分析是一种数据分析方法,用于总结和描述数据集的主要特征和属性。它通常涉及计算各种统计量,如均值、中位数、标准差、最小值、最大值等,以及创建可视化图表,如柱状图、饼图、散点图等,来帮助人们更好地理解数据。以下是描述性分析的一些关键组成部分:
关键组成部分:
-
中心趋势度量:这些统计量帮助我们了解数据的中心位置,包括:
- 均值(平均数):所有数据点的总和除以数据点的数量。
- 中位数:将数据集分为两部分的中间值。
- 众数:数据集中出现次数最多的值。
-
离散度度量:这些统计量描述数据的分散程度,包括:
- 标准差:衡量数据点与均值的平均距离。
- 方差:标准差的平方,表示数据点与均值的平均偏差的平方。
- 四分位数:将数据分为四个部分,用于描述数据的分布。
-
分布形状:描述数据分布的形状,如是否对称、偏斜程度等。
-
可视化图表:通过图表来直观地展示数据的特征,如:
- 柱状图:用于展示分类数据的分布。
- 饼图:用于显示各部分在整体中的占比。
- 散点图:用于展示两个变量之间的关系。
- 箱线图:用于展示数据的分布,包括中位数、四分位数和异常值。
描述性分析的应用:
-
数据探索:在开始更深入的分析之前,通过描述性分析来熟悉数据集。
-
报告制作:使用描述性统计和图表来制作业务报告,向非技术受众传达信息。
-
异常检测:通过描述性分析识别数据中的异常值或离群点,为进一步的调查提供线索。
-
决策支持:提供数据支持,帮助决策者基于数据特征做出更合理的决策。
工具和技术:
-
Excel:提供了一系列的统计函数和图表工具,用于进行描述性分析。
-
Power BI:提供了丰富的可视化选项和简单的数据操作界面,适合商业智能报告。
-
R:一个编程语言和软件环境,专门用于统计分析、图形表示和报告。
-
Python:通过各种库(如Pandas、Matplotlib、Seaborn)进行数据处理和可视化。
认识KPI分析
KPI(Key Performance Indicator,关键绩效指标)分析是一种评估和监控组织、项目或业务流程表现的方法。KPI 是一组定量的、可衡量的指标,用于衡量关键业务目标或结果的达成情况。这些指标通常与组织的战略目标和业务计划紧密相关,并且是衡量组织绩效和进展的重要工具。
KPI 的关键特征:
-
相关性:KPI 应该与组织的战略目标和业务计划直接相关。
-
可量化性:KPI 应该是可衡量的,以便于数据收集和分析。
-
可实现性:KPI 应该是实际可行的,能够通过组织的努力实现。
-
时限性:KPI 应该有时间限制,以便于跟踪和评估进展。
KPI 的类型:
-
财务 KPI:如收入、利润、成本等。
-
运营 KPI:如生产率、库存水平、交货时间等。
-
客户 KPI:如客户满意度、客户保留率、客户获取成本等。
-
员工 KPI:如员工满意度、员工流失率、培训投资回报率等。
-
质量 KPI:如缺陷率、返工率、客户投诉率等。
KPI 分析的步骤:
-
确定目标:明确组织想要实现的目标和战略方向。
-
选择 KPI:根据目标选择相关的 KPI,确保它们能够有效地衡量目标的进展。
-
数据收集:收集用于计算 KPI 的数据。
-
计算 KPI:使用收集到的数据计算 KPI 的值。
-
分析和解释:分析 KPI 的结果,解释它们如何反映组织的表现和进展。
-
报告和沟通:将 KPI 结果以报告的形式呈现,并与利益相关者沟通。
-
采取行动:基于 KPI 分析的结果,制定改进策略和行动计划。
KPI 分析的工具:
-
Excel:提供强大的数据分析和报告功能。
-
Power BI:微软的商业智能工具,用于创建 KPI 仪表板和报告。
-
KPI 管理软件:专门用于管理和分析 KPI 的软件,如 Perigon、Hyperion 等。
Power BI数据分析报表
1. 数据准备
-
导入数据:从各种数据源(如 Excel、SQL Server、CSV 文件等)导入数据。
-
数据清洗和转换:使用 Power BI 的数据导入工具(Power Query)对数据进行清洗、转换和整合。
2. 数据模型构建
-
创建表和关系:在 Power BI 中创建表,并建立表之间的关系。
-
添加计算列:使用 DAX 公式创建计算列,对数据进行计算和转换。
-
定义度量值:使用 DAX 公式创建度量值,用于在报表中进行聚合计算。
3. 创建报表
-
切换到“报表视图”:在 Power BI Desktop 中,点击“新建报表”按钮,进入报表视图。
-
添加视觉元素:从左侧的视觉化元素面板中,将度量值和计算列拖放到报表中。
-
调整视觉元素:根据需要调整视觉元素的样式和布局,以创建清晰、直观的报告。
4. 创建仪表板
-
切换到“仪表板视图”:在报表视图下,点击“新建仪表板”按钮,进入仪表板视图。
-
添加视觉元素:将报表中的视觉元素拖放到仪表板中。
-
调整布局和样式:根据需要调整视觉元素的布局和样式,以创建整洁、一致的仪表板。
5. 分享和发布
-
完成报表和仪表板的设计后,可以将其发布到 Power BI 服务。
-
其他用户可以通过 Power BI 网站或移动应用访问这些报表和仪表板。
数据部署
1. 数据导入
-
打开 Power BI Desktop。
-
点击“获取数据”按钮,选择数据源,如 Excel、SQL Server、CSV 文件等。
-
导入数据,并根据需要进行数据清洗和转换。
2. 数据模型构建
-
在 Power BI 中创建表,并建立表之间的关系。
-
添加计算列,使用 DAX 公式对数据进行计算和转换。
-
定义度量值,用于在报表中进行聚合计算。
3. 创建报表和仪表板
-
切换到“报表视图”,将度量值和计算列拖放到报表中。
-
切换到“仪表板视图”,将报表中的视觉元素拖放到仪表板中。
4. 数据部署
-
完成报表和仪表板的设计后,点击“文件” > “发布” > “发布到 Power BI 服务”。
-
登录 Power BI 服务,选择要发布到的组或工作区。
-
选择要发布的报表和仪表板,点击“发布”。
5. 访问和共享
-
发布完成后,其他用户可以通过 Power BI 网站或移动应用访问这些报表和仪表板。
-
可以设置访问权限,控制谁可以查看和交互报表和仪表板。















