[atguigu@hadoop hive]$ vim /opt/module/hadoop/etc/hadoop/yarn-site.xml <!-- NodeManager使用内存数,默认8G,修改为4G内存 -->(16g物理内存的改为2g或者是3g) <property> <description>Amount of physical memory, in MB, that can be allocated for containers. If set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically calculated(in case of Windows and Linux). In other cases, the default is 8192MB. </description> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 容器最小内存,默认512M --> <property> <description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value </description> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <!-- 容器最大内存,默认8G,修改为4G --> <property> <description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException. </description> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- 虚拟内存检查,默认打开,修改为关闭 -->(使用虚拟内存) <property> <description>Whether virtual memory limits will be enforced for containers.</description> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/log4j-slf4j-impl 2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
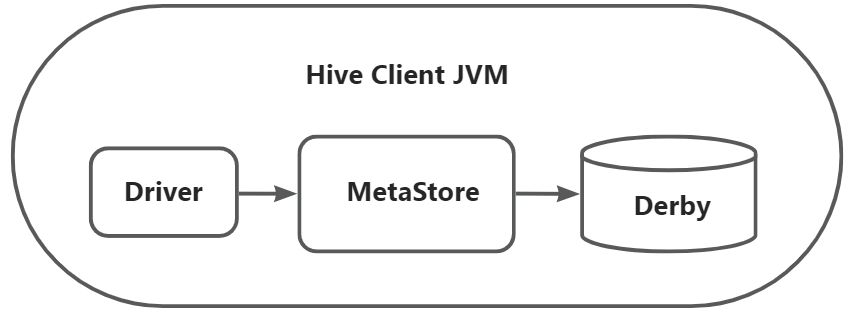
hive> show databases; // 查看当前所有的数据库 OK default Time taken: 0.472 seconds, Fetched: 1 row(s) hive> show tables; // 查看当前所有的表 OK Time taken: 0.044 seconds hive> create table test_derby(id int); // 创建表test_derby,表中只有一个字段,字段类型是 int OK Time taken: 0.474 seconds hive> insert into test_derby values(1001); // 向test_derby表中插入数据 Query ID = atguigu_20211018153727_586935da-100d-4d7e-8a94-063d373cc5dd Total jobs = 3 …… Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 …… Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 12769 HDFS Write: 208 SUCCESS Total MapReduce CPU Time Spent: 6 seconds 190 msec OK Time taken: 31.901 second hive> select * from test_derby; // 查看test_derby表中所有数据 OK 1001 Time taken: 0.085 seconds, Fetched: 1 row(s) hive> exit;
Caused by: ERROR XSDB6: Another instance of Derby may have already booted the database /opt/module/hive/metastore_db. at org.apache.derby.iapi.error.StandardException.newException(Unknown Source) at org.apache.derby.iapi.error.StandardException.newException(Unknown Source) at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.privGetJBMSLockOnDB(Unknown Source) at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.run(Unknown Source) ...